Sub Graph 预处理: Node => NodeItem => TaggedNode (Draft)
引言
下图是一个graph中每个node被处理的过程,首先在ExecutorImpl::Initialize的时候,将node 处理成NodeItem,创建node对应的kernal, 然后在node ready可执行的时候,会创建一个TaggedNode(TaggedNode主要多了个frame指针,记录了当前执行的frame), 并将它放入Ready队列中,最后交给ExecutorState::Process去执行这个Node。
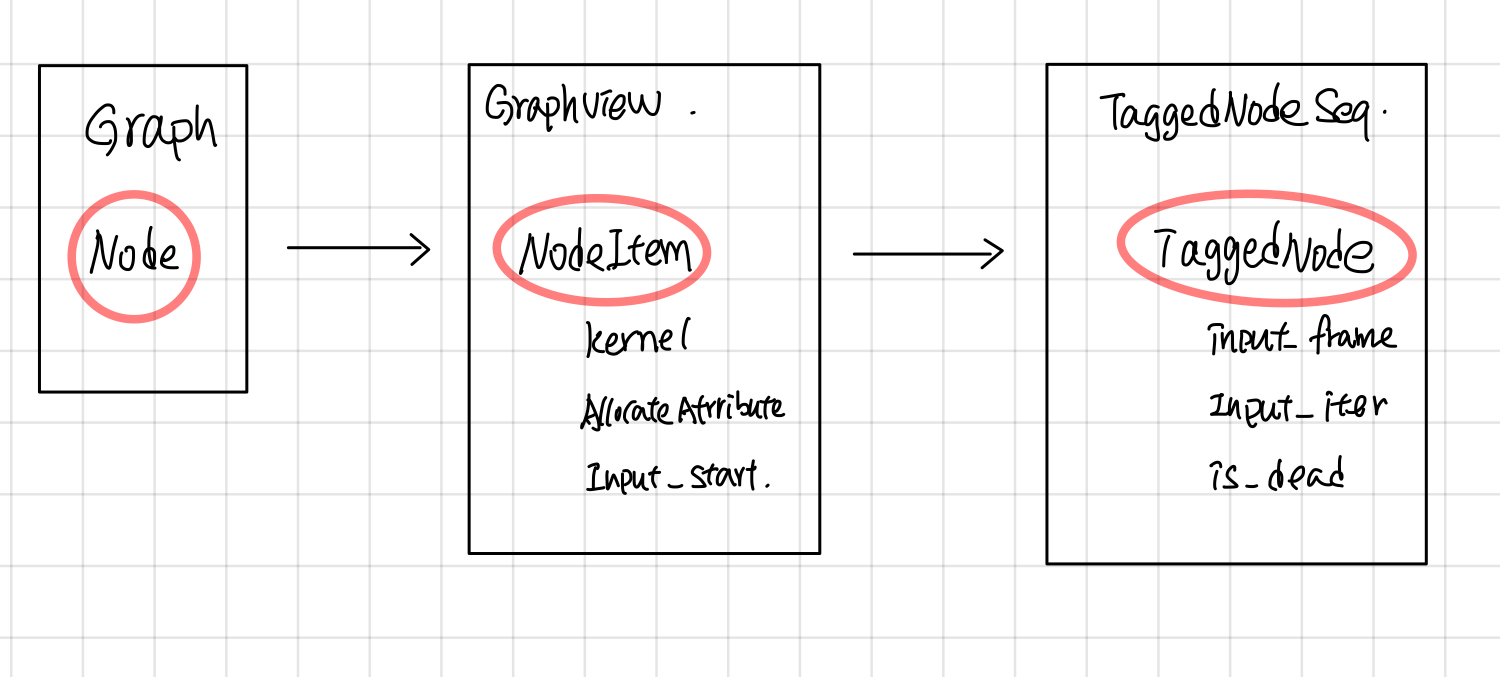
NodeItem
NodeItem的主要作用是将Graph中每个node的op,转换成可以在device上执行的kernal, 另一方面,记录该node输入tensor的位置,并且使用PendingCount来记录Node的执行状态。 Gview可以看成是NodeItem的容器,根据node的id就可以找到相应的NodeItem, 对于graph中的每个node, 在ExecutorImpl::Initialize中都会创建一个NodeItem,放到Gview中。
NodeItem 主要包含的字段
- kernel: 由params.create_kernel创建,kernel是在device上执行的主要对象,kerenl 并将在ExecutorImpl的析构函数被params.delete_kernel删除。
// The kernel for this node.
OpKernel* kernel = nullptr;
- input_start:纪录了在当前IteratorState的input_tensors中开始的index。这个node的输入为:input_tensors[input_start: input_start + num_inputs]这部分对应的Tensors。
// Cached values of node->num_inputs() and node->num_outputs(), to
// avoid levels of indirection.
int num_inputs;
int num_outputs;
// ExecutorImpl::tensors_[input_start] is the 1st positional input
// for this node.
int input_start = 0;
// Number of output edges.
size_t num_output_edges;
- pending_id: 根据这个id在当前的IteratorState中找到对应的PendingCount,从而找到这个nodeItem的执行状态。
PendingCounts::Handle pending_id;
- expensive/async kernel: 标志表明kernel是否是Async的和expensive的。
bool kernel_is_expensive : 1; // True iff kernel->IsExpensive()
bool kernel_is_async : 1; // True iff kernel->AsAsync() != nullptr
- control node ,标志该node是否是Control flow node, 以及类型
bool is_merge : 1; // True iff IsMerge(node)
bool is_enter : 1; // True iff IsEnter(node)
bool is_exit : 1; // True iff IsExit(node)
bool is_control_trigger : 1; // True iff IsControlTrigger(node)
bool is_sink : 1; // True iff IsSink(node)
// True iff IsEnter(node) || IsExit(node) || IsNextIteration(node)
bool is_enter_exit_or_next_iter : 1;
- allocate attribute: 影响device所返回的allocator,从而影响kernal执行时候,申请内存时候的处理行为。
// Return array of per-output allocator attributes.
const AllocatorAttributes* output_attrs() const { return output_attr_base(); }
InferAllocAttr主要根据device, send, recv等节点, 来设置是否是gpu_compatible的,
attr->set_nic_compatible(true);
attr->set_gpu_compatible(true);
其中AllocatorAttributes主要影响GpuDevice所返回的allocator上。
//common_runtime/gpu/gpu_device_factory.cc
Allocator* GetAllocator(AllocatorAttributes attr) override {
if (attr.on_host()) {
if (attr.gpu_compatible() || force_gpu_compatible_) {
ProcessState* ps = ProcessState::singleton();
return ps->GetCUDAHostAllocator(0);
} else {
return cpu_allocator_;
}
} else {
return gpu_allocator_;
}
}
TaggedNode
TaggedNode 增加了了一个FrameState指针,指向了Node将要执行的FrameState, input_iter, input_frame加上input_iter可以确定了
struct TaggedNode {
const Node* node = nullptr;
FrameState* input_frame = nullptr;
int64 input_iter = -1;
bool is_dead = false;
TaggedNode(const Node* t_node, FrameState* in_frame, int64 in_iter,
bool dead) {
node = t_node;
input_frame = in_frame;
input_iter = in_iter;
is_dead = dead;
}
在node处于ready 可执行状态的时候,会创建一个TaggedNode, 并放到TaggedNodeSeq队列中,等待调度执行。
ExecutorState::FrameState::ActivateNodes ==>
ready->push_back(TaggedNode(dst_item->node, this, iter, dst_dead));
ExecutorState::RunAsync ==>
for (const Node* n : impl_->root_nodes_) {
DCHECK_EQ(n->in_edges().size(), 0);
ready.push_back(TaggedNode{n, root_frame_, 0, false});
}
获取node输入tensors指针
首先根据TaggedNode中的input_frame,input_iter获取node的输入tensors
Entry* GetInputTensors(FrameState* input_frame,
int64 input_iter) const NO_THREAD_SAFETY_ANALYSIS {
return input_frame->GetIteration(input_iter)->input_tensors;
}
然后根据NodeItem中定义的input_start获取first_input tensor的指针
//在ExecutorState::Process中:
Entry* input_tensors = GetInputTensors(input_frame, input_iter);
Entry* first_input = input_tensors + item.input_start;